
Stable Diffusion คืออะไร สุดยอด AI สร้างภาพ พร้อมวิธีใช้อย่างละเอียด!


ลองนึกภาพว่าถ้าคุณสามารถวาดภาพได้ด้วยคำพูด เพียงแค่บรรยายสิ่งที่คุณเห็นในหัว แล้วมันก็ปรากฏเป็นภาพตรงหน้าคุณ มันคงจะสุดยอดมาก ๆ เลยใช่ไหม? และนี่เองคือสิ่งที่ Stable Diffusion สามารถทำได้ ไม่ว่าคุณจะเป็นศิลปิน นักการตลาด นักพัฒนาเกม หรือแค่คนที่ชอบสร้างสรรค์ Stable Diffusion เปิดโอกาสให้คุณสร้างภาพที่คุณฝันถึงได้อย่างง่ายดาย เพียงแค่พิมพ์คำอธิบาย แล้วปล่อยให้ AI ทำหน้าที่วาดภาพให้คุณ
ในบทความนี้ เราจะพาคุณเจาะลึกว่า AI นี้ทำงานอย่างไร มันสามารถทำอะไรได้บ้าง วิธีการใช้งานอย่างละเอียด รวมถึงข้อจำกัดและประเด็นที่น่าสนใจเกี่ยวกับ AI ตัวนี้ เพื่อให้ผู้อ่านเข้าใจภาพรวมของเทคโนโลยีนี้ได้อย่างครบถ้วน
Stable Diffusion คืออะไร
Stable Diffusion AI เป็นโมเดลการแพร่กระจายเชิงลึก (deep learning diffusion model) ที่ใช้ในการสร้างภาพจากข้อความ (text-to-image generation) โดยพัฒนาโดยกลุ่มวิจัย CompVis ที่มหาวิทยาลัย Ludwig Maximilian ในเมืองมิวนิก และได้รับการสนับสนุนจาก Stability AI และองค์กรไม่แสวงหาผลกำไร LAION
การทำงานของโมเดล
โมเดลนี้ทำงานโดยการเพิ่มสัญญาณรบกวนแบบเกาส์เซียน (Gaussian noise) ไปยังภาพในพื้นที่แฝง และใช้ U-Net ค่อยๆ ลบสัญญาณรบกวนออกทีละขั้นตอน โดยใช้ข้อมูลจากข้อความที่ป้อนเข้าไปเป็นตัวควบคุมทิศทางการลบสัญญาณรบกวน เพื่อสร้างภาพใหม่ที่มีความหมายตามข้อความที่กำหนด การทำงานนี้ช่วยให้ Stable Diffusion สามารถสร้างภาพได้เร็วกว่าโมเดลอื่นๆ ที่ทำงานกับพิกเซลโดยตรง ทำให้สามารถรันบนฮาร์ดแวร์ทั่วไปได้ นอกจากนี้ยังสามารถควบคุมกระบวนการสร้างภาพได้ละเอียดมากขึ้น เช่น การกำหนดจำนวนขั้นตอนในการลบสัญญาณรบกวน หรือการใช้ภาพต้นแบบเป็นจุดเริ่มต้นแทนสัญญาณรบกวนสุ่ม โดยโครงสร้างของโมเดลจะมี 3 ส่วนหลัก ๆ
- Variational Autoencoder (VAE): ทำหน้าที่บีบอัดภาพจากพื้นที่พิกเซลไปยังพื้นที่แฝง (latent space) ที่มีมิติเล็กลง เพื่อจับความหมายเชิงสัญลักษณ์ของภาพ
- U-Net: ใช้ในการลบสัญญาณรบกวน (denoise) จากการแพร่กระจายไปข้างหน้า (forward diffusion) กลับไปยังพื้นที่แฝง
- Text Encoder: ใช้ในการแปลงข้อความเป็นเวกเตอร์ฝังตัว (embedding) โดยใช้ CLIP ViT-L/14 text encoder
Stable Diffusion ทำอะไรได้บ้าง

Stable Diffusion มีการใช้งานที่หลากหลายในการสร้างสรรค์ภาพและศิลปะดิจิทัล โดยสามารถนำไปใช้ในหลายบริบท ดังนี้:
การสร้างภาพจากข้อความ (Text-to-Image Generation)
สามารถสร้างภาพที่มีความหมายตามข้อความที่กำหนดได้ ตัวอย่างเช่น การป้อนข้อความว่า "แมวกำลังนั่งอยู่บนเก้าอี้" โมเดลจะสร้างภาพที่สอดคล้องกับคำอธิบายนั้น
การเติมเต็มภาพ (Inpainting)
โมเดลสามารถเติมเต็มส่วนที่ขาดหายไปของภาพได้ เช่น การลบวัตถุออกจากภาพแล้วให้โมเดลเติมเต็มส่วนที่ว่างเปล่าด้วยเนื้อหาที่เหมาะสม
การขยายภาพ (Outpainting)
สามารถขยายขอบเขตของภาพโดยการสร้างเนื้อหาเพิ่มเติมที่สอดคล้องกับภาพต้นฉบับ ตัวอย่างเช่น การขยายภาพจากขนาด 4:3 เป็น 16:9 โดยการเพิ่มเนื้อหาที่เหมาะสมทางด้านข้าง
การแปลงภาพตามคำสั่งข้อความ (Image-to-Image Translation)
โมเดลสามารถแปลงภาพหนึ่งไปเป็นอีกภาพหนึ่งตามคำสั่งข้อความได้ เช่น การแปลงภาพถ่ายให้เป็นภาพวาดสไตล์ต่างๆ หรือการเปลี่ยนสีของวัตถุในภาพตามคำสั่ง
การสร้างภาพศิลปะ (Art Generation)
สามารถใช้ในการสร้างภาพศิลปะที่มีความซับซ้อนและสวยงามตามสไตล์ที่ต้องการ เช่น การสร้างภาพวาดสไตล์วินเทจหรือภาพวาดสไตล์โมเดิร์น
การสร้างภาพสำหรับเกมและภาพยนตร์ (Game and Movie Asset Creation)
โมเดลสามารถใช้ในการสร้างภาพและองค์ประกอบต่างๆ สำหรับเกมและภาพยนตร์ เช่น การสร้างฉากหลัง ตัวละคร หรือวัตถุต่างๆ ที่ใช้ในงานผลิต
การสร้างภาพสำหรับการตลาดและโฆษณา (Marketing and Advertising)
สามารถใช้ในการสร้างภาพที่น่าสนใจและดึงดูดสำหรับการตลาดและโฆษณา เช่น การสร้างภาพผลิตภัณฑ์ในบริบทต่างๆ หรือการสร้างภาพแคมเปญโฆษณา
การสร้างภาพสำหรับการศึกษาและวิจัย (Educational and Research Purposes)
โมเดลสามารถใช้ในการสร้างภาพสำหรับการศึกษาและวิจัย เช่น การสร้างภาพประกอบสำหรับหนังสือเรียนหรือการสร้างภาพจำลองสำหรับการวิจัยทางวิทยาศาสตร์
Stable Diffusionถือเป็นเครื่องมือที่มีความยืดหยุ่นและสามารถนำไปใช้ในหลายบริบทของการสร้างสรรค์ภาพและศิลปะดิจิทัล ทำให้เป็นที่นิยมในวงการต่างๆ ที่ต้องการการสร้างภาพที่มีคุณภาพสูงและมีความหมายตามที่ต้องการ
วิธีใช้ Stable Diffusion แบบ Step-by-step
วิธีใช้ Stable Diffusion อย่างละเอียดมีดังนี้:
1. เลือกโมเดล (Checkpoint) ที่เหมาะสม:
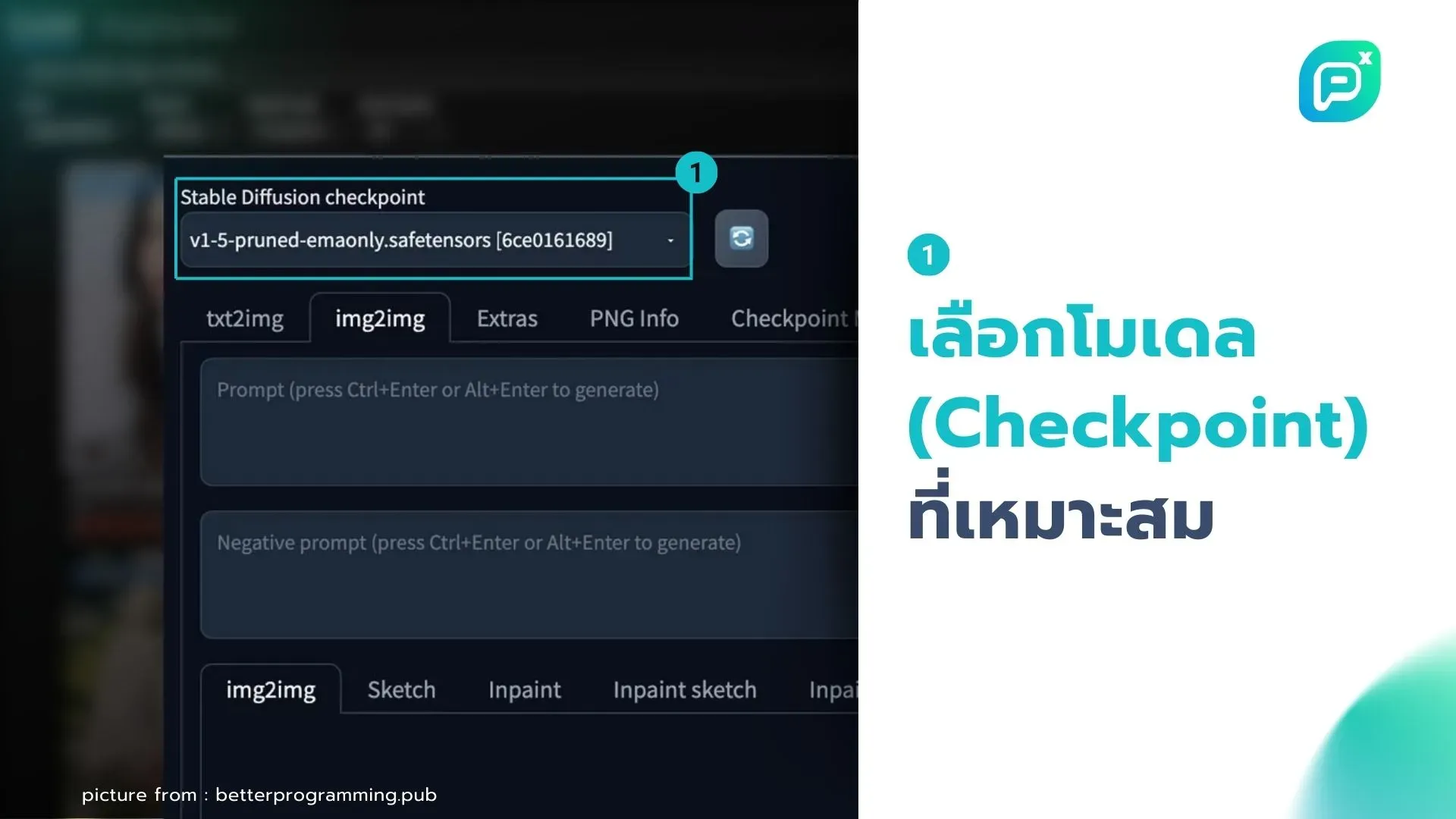
- สำหรับงานสถาปัตยกรรม แนะนำโมเดลเช่น ArchitectureRealMix หรือ SDXL
- โมเดลทั่วไปที่ใช้ได้ดีคือ Stable Diffusion XL, DreamShaper XL
2. เขียนคำอธิบาย (Prompt):
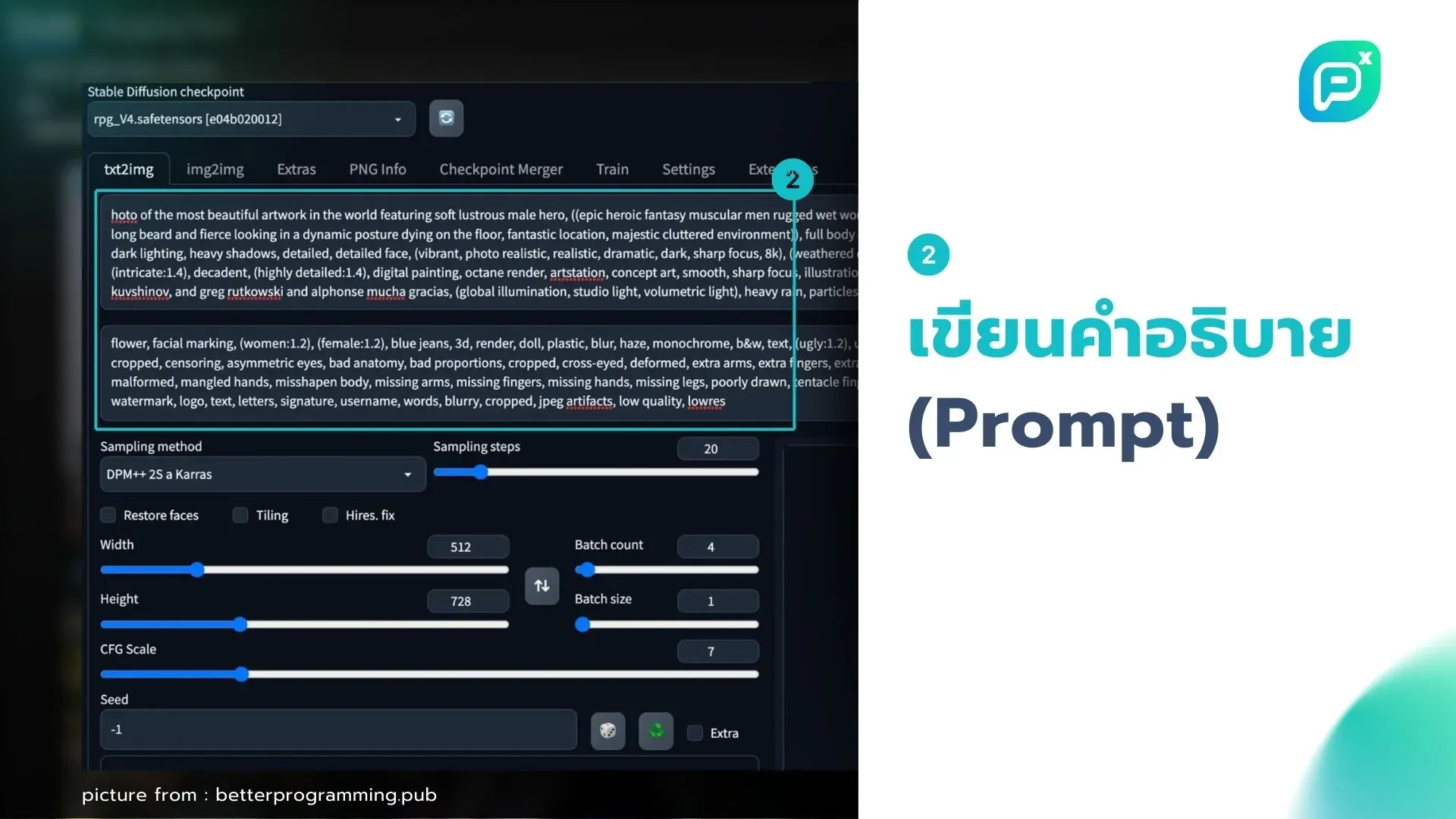
- อธิบายภาพที่ต้องการอย่างละเอียด เช่น สไตล์ มุมมอง วัสดุ บรรยากาศ
- ใช้คำสำคัญเฉพาะทาง เช่น "parametric style", "exterior view", "lace-like wood"
- ระบุศิลปินหรือสไตล์ที่ต้องการ เช่น "inspired by Zaha Hadid"
3. ปรับค่าพารามิเตอร์:
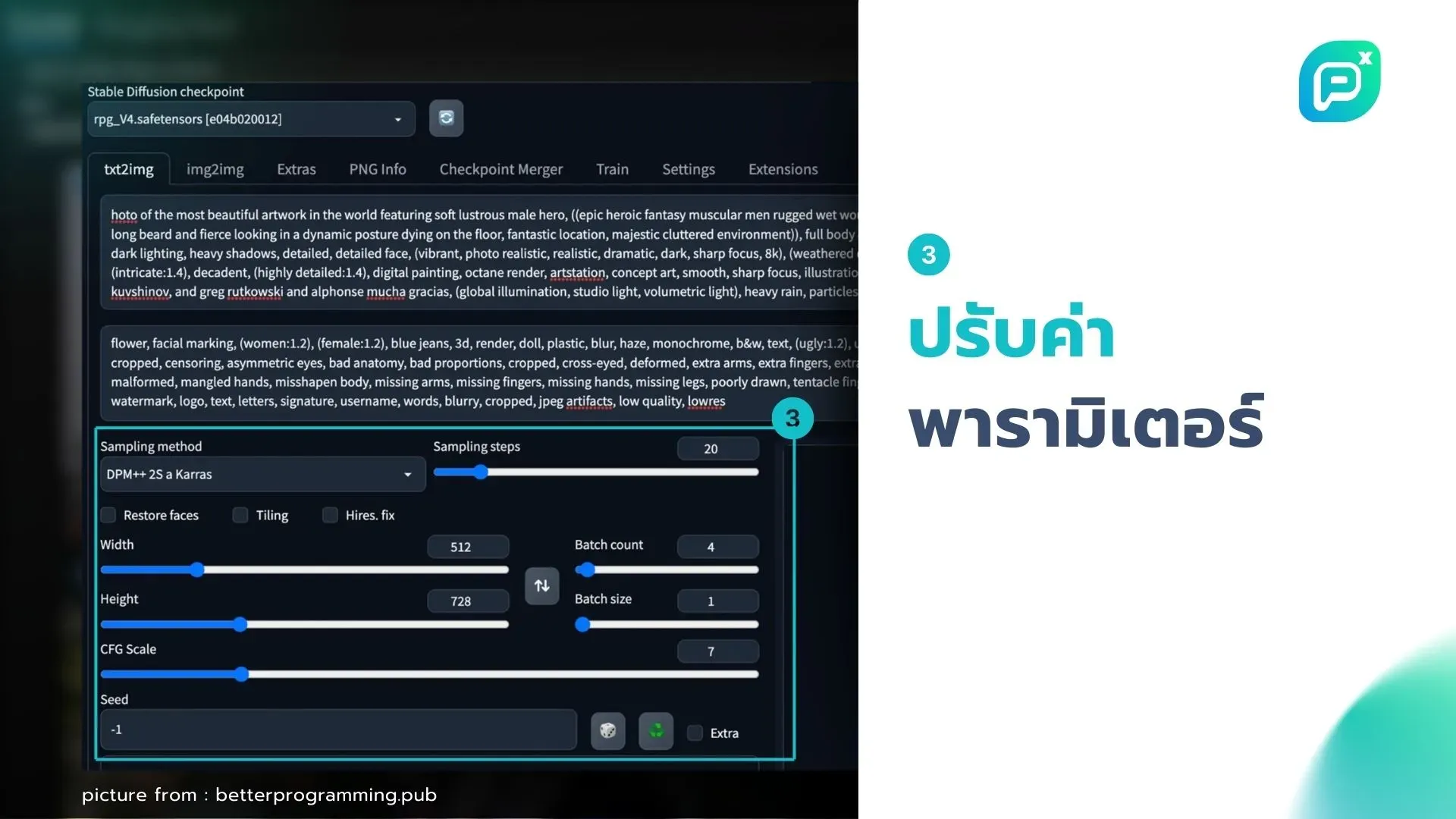
- Sampling method: เลือกวิธีที่เหมาะสม เช่น Euler a
- Sampling steps: เพิ่มขึ้นเพื่อคุณภาพที่ดีขึ้น (20-50 steps)
- CFG Scale: ปรับความสอดคล้องกับ prompt (7-12 ค่าปกติ)
- Seed: กำหนดค่าเพื่อสร้างภาพซ้ำได้
4. ใช้ ControlNet (ถ้ามี):
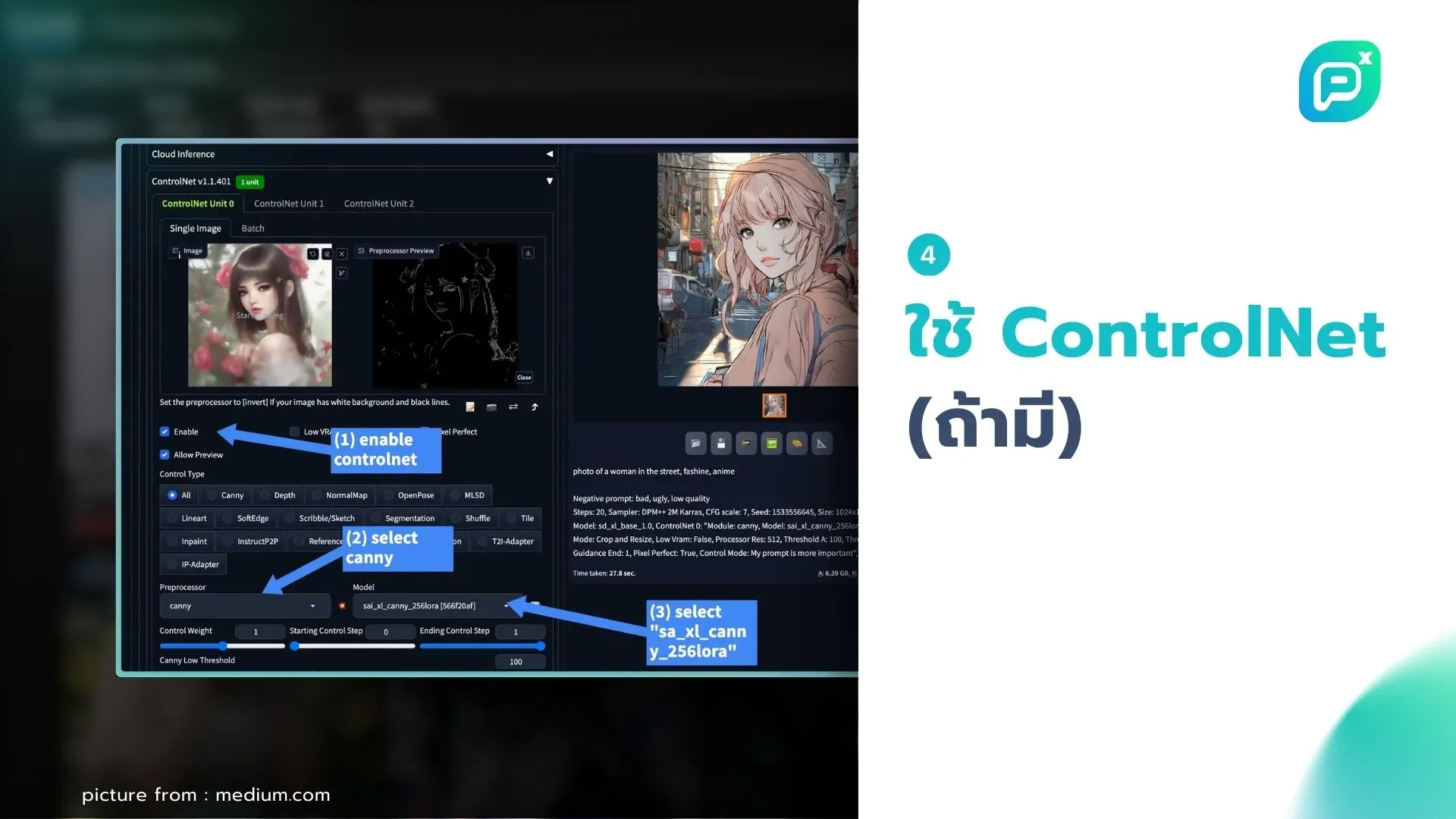
- อัพโหลดภาพต้นแบบเพื่อควบคุมโครงสร้างหรือองค์ประกอบ
- เลือกโหมด ControlNet ที่เหมาะสม เช่น Canny edge detection
5. สร้างภาพ:
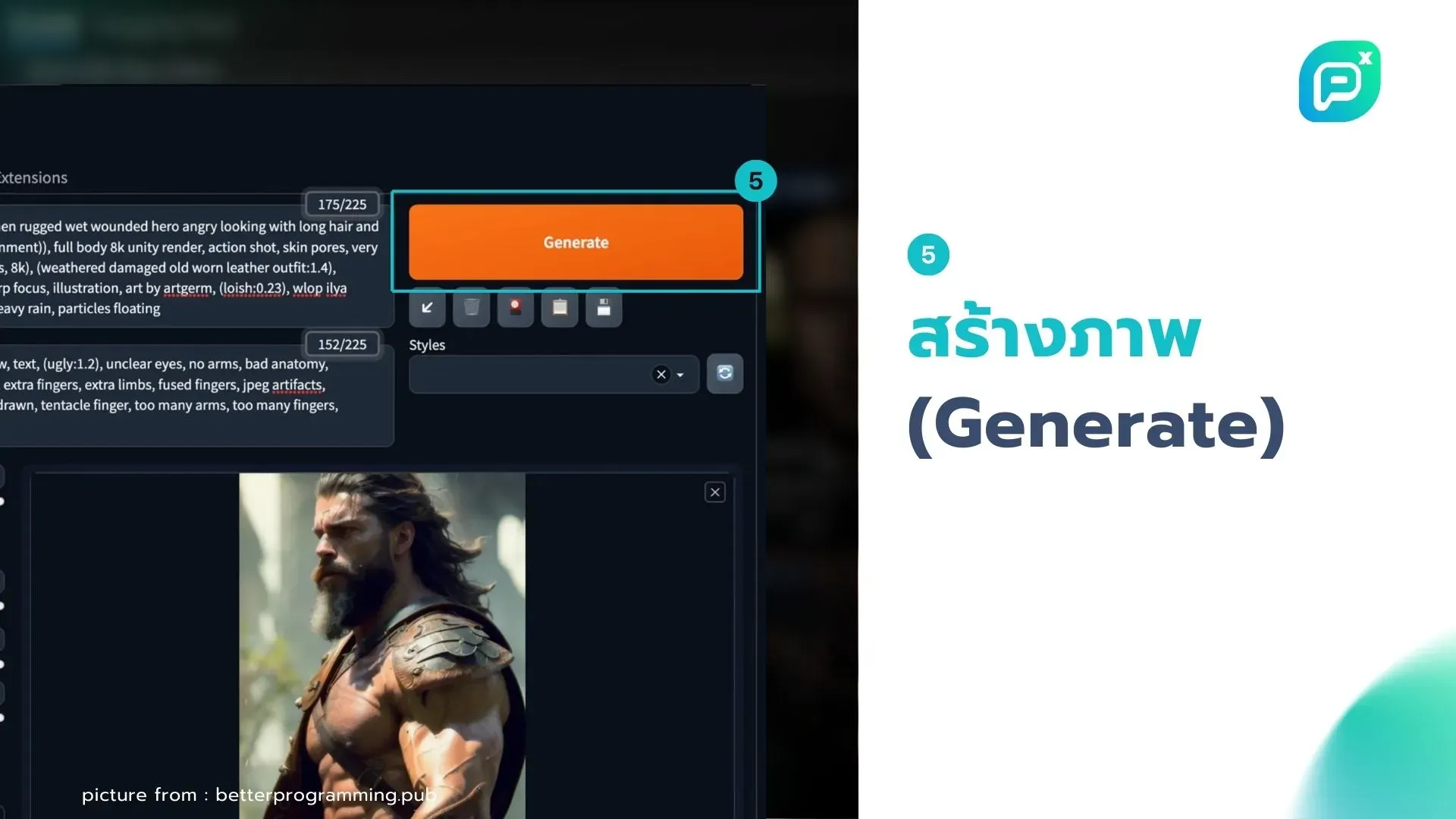
- กดปุ่ม Generate เพื่อสร้างภาพ
- ทดลองปรับ prompt และค่าต่างๆ เพื่อผลลัพธ์ที่ดีขึ้น
6. ปรับแต่งเพิ่มเติม:
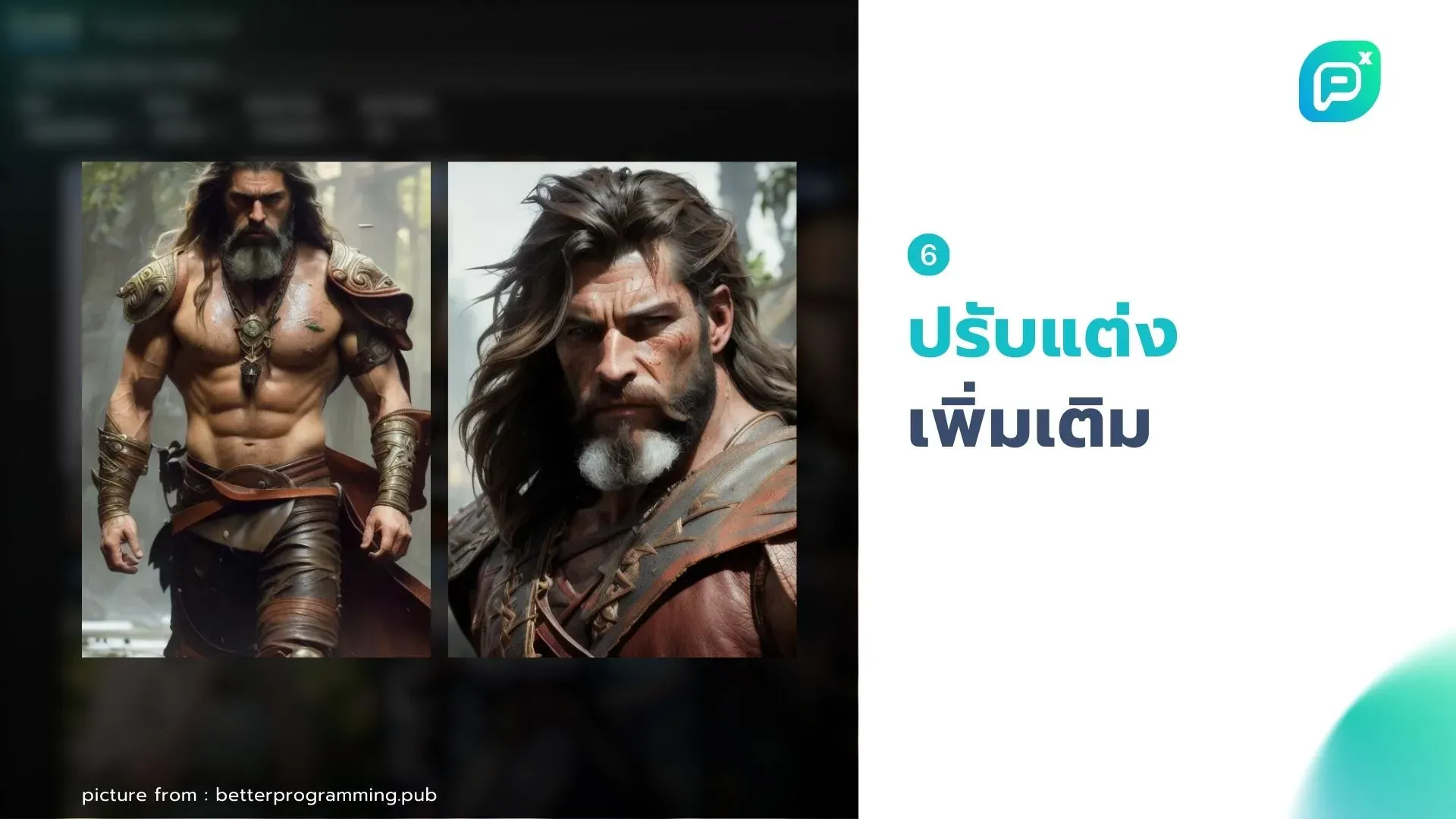
- ใช้ Inpainting เพื่อแก้ไขบางส่วนของภาพ
- ใช้ Upscaler เพื่อเพิ่มความละเอียด
7. เทคนิคเพิ่มเติม:
- ใช้ XYZ Plot เพื่อทดลองค่าต่างๆ พร้อมกัน
- ลองใช้ Checkpoint Merger เพื่อผสมโมเดลต่างๆ
8. ฝึกฝนและทดลอง:
- ศึกษาตัวอย่าง prompt จากแหล่งต่างๆ
- ทดลองใช้โมเดลและ LoRA เฉพาะทางสำหรับงานสถาปัตยกรรม
การใช้ Stable Diffusion ให้ได้ผลดีต้องอาศัยการฝึกฝนและทดลอง ปรับแต่งค่าต่างๆ ให้เหมาะกับงานแต่ละชิ้น และเรียนรู้เทคนิคใหม่ๆ อยู่เสมอ
คำแนะนำในการสร้าง Prompt สำหรับ Stable Diffusion:
- ระบุประเภทของภาพที่ต้องการ เช่น digital illustration, photo, portrait
- อธิบายรายละเอียดของสิ่งที่ต้องการให้ปรากฏในภาพ
- ระบุสไตล์ศิลปะหรือชื่อศิลปินที่ต้องการให้มีอิทธิพลต่อภาพ
- เพิ่มคำอธิบายเกี่ยวกับคุณภาพของภาพ เช่น 4k, detailed, vivid colors
- ใช้คำที่บ่งบอกถึงบรรยากาศหรืออารมณ์ของภาพ
ทำไม Stable Diffusion จึงเป็นสุดยอดเครื่องมือในการสร้างภาพ
Stable Diffusion เป็นเครื่องมือ สร้างภาพด้วย AI ที่มีจุดแข็งหลายประการที่ทำให้มันเป็นเครื่องมือที่มีประสิทธิภาพและน่าสนใจสำหรับการใช้งานในหลากหลายอุตสาหกรรม ได้แก่
1. ความสามารถในการสร้างภาพที่มีรายละเอียดสูง
Stable Diffusion สามารถสร้างภาพที่มีความละเอียดและรายละเอียดสูงจากคำอธิบายข้อความได้อย่างแม่นยำ ซึ่งเป็นประโยชน์อย่างมากสำหรับการสร้างสรรค์งานศิลปะดิจิทัล การออกแบบผลิตภัณฑ์ และการสร้างเนื้อหาสำหรับการตลาดและโฆษณา
2. การทำงานในพื้นที่แฝง (Latent Space)
โมเดลนี้ทำงานในพื้นที่แฝงซึ่งมีมิติที่เล็กกว่าพื้นที่พิกเซล ทำให้การคำนวณมีประสิทธิภาพมากขึ้นและสามารถรันได้บนฮาร์ดแวร์ทั่วไป เช่น GPU ของผู้บริโภค การทำงานในพื้นที่แฝงยังช่วยให้สามารถสร้างภาพได้เร็วขึ้นและมีความยืดหยุ่นในการปรับแต่งภาพตามความต้องการของผู้ใช้
3. การใช้งานที่หลากหลาย
Stable Diffusion ไม่ได้จำกัดเพียงการสร้างภาพจากข้อความเท่านั้น แต่ยังสามารถใช้ในการเติมเต็มภาพ (inpainting), การขยายภาพ (outpainting), และการแปลงภาพตามคำสั่งข้อความ (image-to-image translation) ได้อีกด้วย นอกจากนี้ยังสามารถใช้ในการแก้ไขภาพที่มีอยู่ เช่น การเพิ่มหรือลบวัตถุ การเปลี่ยนสี หรือการปรับแต่งองค์ประกอบต่างๆ ในภาพ
4. การเข้าถึงและการใช้งานที่ง่าย
Stable Diffusion เป็นโมเดลโอเพนซอร์สที่สามารถดาวน์โหลดและใช้งานได้ฟรี ทำให้ผู้ใช้ทั่วไปสามารถเข้าถึงเทคโนโลยีนี้ได้โดยไม่ต้องพึ่งพาบริการคลาวด์ที่มีค่าใช้จ่ายสูง นอกจากนี้ยังมีแพลตฟอร์มออนไลน์และบริการคลาวด์ที่ให้บริการ Stable Diffusion ทำให้การใช้งานสะดวกและง่ายดายยิ่งขึ้น
5. การเรียนรู้และปรับปรุงอย่างต่อเนื่อง
โมเดลนี้มีความสามารถในการเรียนรู้และปรับปรุงผลลัพธ์อย่างต่อเนื่องจากการใช้งานของผู้ใช้ ทำให้สามารถสร้างภาพที่มีความแม่นยำและสมจริงมากขึ้นเมื่อเวลาผ่านไป
6. การประยุกต์ใช้งานในหลายอุตสาหกรรม
Stable Diffusion ถูกนำไปใช้ในหลากหลายอุตสาหกรรม เช่น การสร้างสินทรัพย์สำหรับเกม การออกแบบผลิตภัณฑ์ การตลาดและโฆษณา การวิจัยทางวิทยาศาสตร์ และการแพทย์ ความสามารถในการสร้างภาพที่มีคุณภาพสูงและการปรับแต่งตามความต้องการทำให้มันเป็นเครื่องมือที่มีคุณค่าในหลายบริบท
ด้วยจุดแข็งเหล่านี้ โมเดลนี้จึงเป็นเครื่องมือที่มีประสิทธิภาพและมีความยืดหยุ่นสูงในการสร้างสรรค์ภาพและเนื้อหาดิจิทัลในหลากหลายอุตสาหกรรม
ข้อดี-ข้อเสียของ Stable Diffusion

ข้อดี
- ใช้งานง่าย สามารถสร้างภาพคุณภาพสูงได้อย่างรวดเร็วด้วยการป้อนข้อความเพียงไม่กี่คำ
- มีความยืดหยุ่นสูง สามารถปรับแต่งพารามิเตอร์ต่างๆ เพื่อควบคุมผลลัพธ์ได้
- สร้างภาพที่มีรายละเอียดและความสวยงามสูง เหมาะสำหรับงานออกแบบและสร้างสรรค์
- เป็นโอเพนซอร์ส สามารถนำไปพัฒนาต่อยอดได้
- ประหยัดต้นทุนและเวลาในการสร้างภาพ โดยเฉพาะสำหรับธุรกิจขนาดเล็ก
- มีความสามารถหลากหลาย เช่น การสร้างภาพจากข้อความ การแก้ไขภาพ การขยายภาพ
ข้อเสีย
- มีปัญหาในการสร้างภาพที่มีความสมจริงของร่างกายมนุษย์ โดยเฉพาะมือและแขนขา
- ต้องใช้ฮาร์ดแวร์ที่มีประสิทธิภาพสูง โดยเฉพาะ GPU ที่มี VRAM มากพอ
- อาจมีปัญหาด้านลิขสิทธิ์และกฎหมาย เนื่องจากยังไม่มีความชัดเจนในเรื่องการคุ้มครองผลงาน AI
- ต้องใช้เวลาในการเรียนรู้และฝึกฝนเพื่อให้ได้ผลลัพธ์ที่ดี
- อาจสร้างภาพที่ซ้ำซ้อนหรือคล้ายคลึงกันได้ หากใช้คำสำคัญที่คล้ายกัน
- ยังมีข้อจำกัดในการสร้างภาพที่มีความซับซ้อนหรือเฉพาะเจาะจงมากๆ
แม้ว่าโมเดลนี้จะมีความซับซ้อนในการใช้งานสำหรับผู้เริ่มต้น แต่ศักยภาพและความยืดหยุ่นของมันทำให้คุ้มค่ากับการเรียนรู้และฝึกฝน การเป็นโมเดลแบบเปิด (open-source) ยังเปิดโอกาสให้เกิดการพัฒนาและปรับปรุงอย่างต่อเนื่องจากชุมชนนักพัฒนาทั่วโลก
ท้ายที่สุด Stable Diffusion ไม่ใช่แค่เครื่องมือ แต่เป็นประตูสู่โลกแห่งความเป็นไปได้ที่ไร้ขีดจำกัด มันท้าทายให้เราคิดใหม่เกี่ยวกับความคิดสร้างสรรค์ การสื่อสารด้วยภาพ และบทบาทของ AI ในศิลปะและการออกแบบ เมื่อเราก้าวเข้าสู่ยุคใหม่ของการสร้างภาพด้วย AI โมเดลนี้จะยังคงเป็นเครื่องมือสำคัญที่ขับเคลื่อนนวัตกรรมและสร้างแรงบันดาลใจให้กับผู้สร้างสรรค์ทั่วโลก
หากไม่อยากพลาดความรู้ดี ๆ แบบนี้ สามารถติดตาม Prompt Expert ตามช่องทางด้านล่างได้เลย
Website: prompt-expert.co
Facebook Page: Prompt-Expert



