
Nvidia และ Mistral AI ร่วมกันเปิดตัว Language Model ตัวใหม่ สำหรับใช้ในองค์กรโดยเฉพาะ
Nvidia และ Mistral AI ร่วมกันเปิดตัว Mistral-NeMo โมเดลภาษา AI ขนาด 12 พันล้านพารามิเตอร์ที่ทรงพลังสำหรับการใช้งานในองค์กรโดยเฉพาะ


Key takeaways
- Nvidia และ Mistral AI ร่วมกันเปิดตัว Language Model ใหม่ชื่อ Mistral-NeMo ที่มี 12 พันล้านพารามิเตอร์ และ token context window ขนาด 128,000 ตัว เพื่อนำความสามารถ AI ระดับสูงมาสู่เดสก์ท็อปธุรกิจโดยตรง
- โมเดลนี้มีขนาดกะทัดรัดแต่ทรงพลัง สามารถรันบนฮาร์ดแวร์ขององค์กรได้ ตอบโจทย์ความกังวลเรื่องความเป็นส่วนตัวของข้อมูล ความต้องการ latency ต่ำ และความคุ้มค่า
- Context window ที่กว้างของ Mistral-NeMo มีประโยชน์มากสำหรับธุรกิจที่ต้องจัดการกับเอกสารยาว การวิเคราะห์ซับซ้อน หรือโค้ดที่ซับซ้อน ช่วยให้ได้ output ที่สอดคล้องและคงเส้นคงวามากขึ้น
- การเปิดตัวนี้ถือเป็นก้าวสำคัญในการทำให้ AI เข้าถึงได้ง่ายขึ้นกว่าเดิมหลายเท่า
Nvidia และ Mistral AI สตาร์ทอัพจากฝรั่งเศส ร่วมกันประกาศเปิดตัว Language Model ตัวใหม่ในวันนี้ ซึ่งออกแบบมาเพื่อนำขีดความสามารถของ AI ที่ทรงพลังมาสู่เดสก์ท็อปธุรกิจโดยตรง โมเดลที่มีชื่อว่า Mistral-NeMo นี้ มีพารามิเตอร์ถึง 12 พันล้านตัว และมี token context window กว้างถึง 128,000 ตัว ทำให้เป็นเครื่องมือที่น่าเกรงขามสำหรับธุรกิจที่ต้องการใช้ AI โซลูชัน โดยไม่จำเป็นต้องพึ่งพา cloud resources มากนัก
Bryan Catanzaro รองประธานฝ่ายวิจัย Applied Deep Learning ของ Nvidia ได้เน้นย้ำถึงการเข้าถึงได้ง่ายและประสิทธิภาพของโมเดลนี้ในการให้สัมภาษณ์ล่าสุดกับ VentureBeat "เรากำลังเปิดตัวโมเดลที่เราร่วมกัน train กับ Mistral มันเป็นโมเดลขนาด 12 พันล้านพารามิเตอร์ และเราเปิดตัวภายใต้ Apache 2.0 license" เขากล่าว "เรารู้สึกตื่นเต้นมากกับความแม่นยำของโมเดลนี้ในหลากหลาย tasks"
ความร่วมมือระหว่าง Nvidia ยักษ์ใหญ่ด้านการผลิต GPU และฮาร์ดแวร์ AI กับ Mistral AI ดาวรุ่งในวงการ AI ของยุโรป ถือเป็นการเปลี่ยนแปลงครั้งสำคัญในแนวทางของอุตสาหกรรม AI สำหรับโซลูชันองค์กร โดยมุ่งเน้นไปที่โมเดลที่กะทัดรัดแต่ทรงพลังมากขึ้น ความร่วมมือนี้มีเป้าหมายเพื่อทำให้การเข้าถึงขีดความสามารถของ AI ขั้นสูงนั้นเข้าถึงได้ง่ายมากขึ้น
Catanzaro ได้อธิบายถึงข้อดีของโมเดลขนาดเล็กเพิ่มเติมว่า "โมเดลที่เล็กลงนั้นเข้าถึงได้ง่ายกว่ามาก พวกมันรันง่ายกว่า และโมเดลธุรกิจก็สามารถแตกต่างออกไปได้ เพราะผู้คนสามารถรันพวกมันบนระบบของตัวเองที่บ้านได้ ในความเป็นจริงแล้ว โมเดลนี้สามารถรันบน RTX GPU ที่หลายคนมีอยู่แล้วได้เลย"
พัฒนาการนี้มาในช่วงเวลาสำคัญของอุตสาหกรรม AI ขณะที่ความสนใจส่วนใหญ่มุ่งไปที่โมเดลขนาดใหญ่อย่าง GPT-4 ของ OpenAI ที่มีพารามิเตอร์หลายแสนล้านตัว ก็มีความสนใจเพิ่มขึ้นในโมเดลที่มีประสิทธิภาพมากขึ้นซึ่งสามารถรันแบบ บนฮาร์ดแวร์ขององค์กรได้ การเปลี่ยนแปลงนี้ถูกขับเคลื่อนด้วยความกังวลเรื่องความเป็นส่วนตัวของข้อมูล ความต้องการ latency ที่ต่ำลง และความต้องการโซลูชัน AI ที่คุ้มค่ามากขึ้น
Token context window ขนาด 128,000 ตัวของ Mistral-NeMo ถือเป็นคุณสมบัติเด่น ช่วยให้โมเดลสามารถประมวลผลและเข้าใจข้อความขนาดใหญ่ได้มากกว่าคู่แข่งหลายราย "เราคิดว่าความสามารถด้าน long context นั้นสำคัญสำหรับหลายแอปพลิเคชัน" Catanzaro กล่าว "ถ้าพวกเขาสามารถหลีกเลี่ยงการ fine-tuning ได้ มันจะทำให้ deploy ง่ายขึ้นมาก"
ทำไมบริบท (Context) จึงสำคัญอย่างมากในการใช้ AI
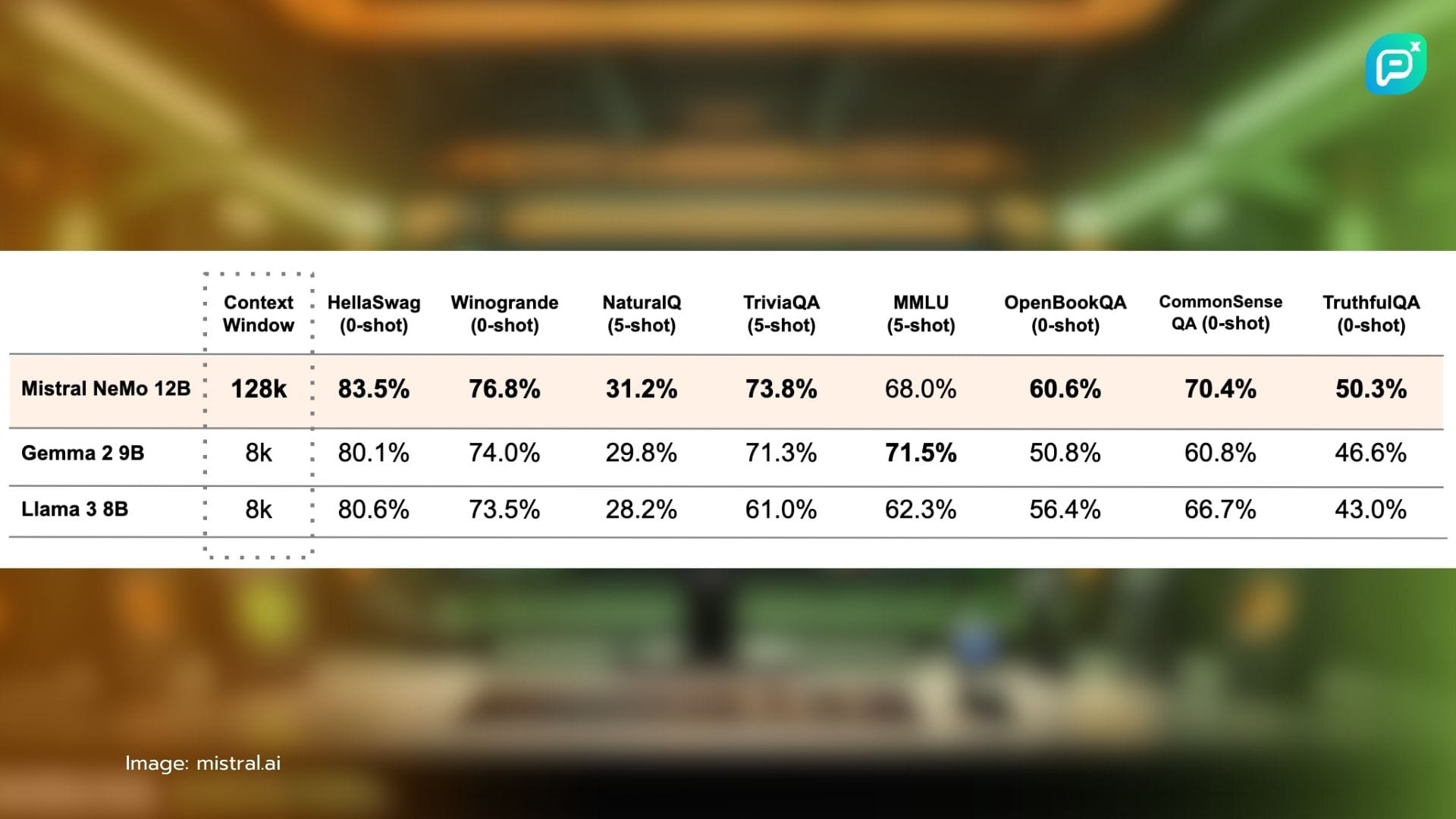
context window ที่กว้างขึ้นนี้อาจมีประโยชน์อย่างมากสำหรับธุรกิจที่ต้องจัดการกับเอกสารที่ยาว การวิเคราะห์ที่ซับซ้อน หรืองานเขียนโค้ดที่ซับซ้อน มันอาจช่วยกำจัดความจำเป็นในการ refresh context บ่อยๆ นำไปสู่ output ที่สอดคล้องและคงเส้นคงวามากขึ้น
ประสิทธิภาพและความสามารถในการ deploy แบบ local ของโมเดลนี้อาจดึงดูดธุรกิจที่ทำงานในสภาพแวดล้อมที่มีการเชื่อมต่ออินเทอร์เน็ตจำกัด หรือที่มีข้อกำหนดด้านความเป็นส่วนตัวของข้อมูลอย่างเข้มงวด อย่างไรก็ตาม Catanzaro ได้ชี้แจงถึงกรณีการใช้งานที่ตั้งใจของโมเดลนี้ว่า "ผมคิดว่ามันเหมาะสำหรับแล็ปท็อปและพีซีมากกว่าสมาร์ทโฟน"
การวางตำแหน่งนี้บ่งชี้ว่า แม้ Mistral-NeMo จะนำ AI เข้าใกล้ผู้ใช้ธุรกิจแต่ละรายมากขึ้น แต่ก็ยังไม่ถึงขั้นที่จะใช้งานบนมือถือได้
นักวิเคราะห์ในอุตสาหกรรมเสนอว่า การเปิดตัวครั้งนี้อาจส่งผลกระทบอย่างมากต่อตลาดซอฟต์แวร์ AI การเปิดตัว Mistral-NeMo นับเป็นการเปลี่ยนแปลงที่อาจเกิดขึ้นในการใช้ AI ขององค์กร ด้วยการนำเสนอโมเดลที่สามารถรันได้อย่างมีประสิทธิภาพบนฮาร์ดแวร์ local Nvidia และ Mistral AI กำลังจัดการกับข้อกังวลที่ขัดขวางการนำ AI ไปใช้อย่างแพร่หลายในหลายธุรกิจ เช่น ความเป็นส่วนตัวของข้อมูล latency และต้นทุนสูงที่เกี่ยวข้องกับโซลูชันบน cloud
การเคลื่อนไหวนี้อาจทำให้สนามแข่งขันเท่าเทียมกันมากขึ้น ช่วยให้ธุรกิจขนาดเล็กที่มีทรัพยากรจำกัดสามารถใช้ประโยชน์จากความสามารถของ AI ที่ก่อนหน้านี้เข้าถึงได้เฉพาะบริษัทใหญ่ที่มีงบ IT มหาศาลเท่านั้น อย่างไรก็ตาม ผลกระทบที่แท้จริงของพัฒนาการนี้จะขึ้นอยู่กับประสิทธิภาพของโมเดลในแอปพลิเคชันจริง และระบบนิเวศของเครื่องมือและการสนับสนุนที่พัฒนาขึ้นรอบๆ มัน
โมเดลนี้พร้อมใช้งานทันทีในรูปแบบ NVIDIA NIM inference microservice โดยมีแผนจะปล่อยเวอร์ชันที่ดาวน์โหลดได้ในอนาคตอันใกล้ การเปิดตัวภายใต้ Apache 2.0 license อนุญาตให้ใช้งานเชิงพาณิชย์ได้ ซึ่งอาจเร่งการนำไปใช้ในสภาพแวดล้อมขององค์กร
การแข่งขันเพื่อให้ทุกคนสามารถเข้าถึง AI ได้
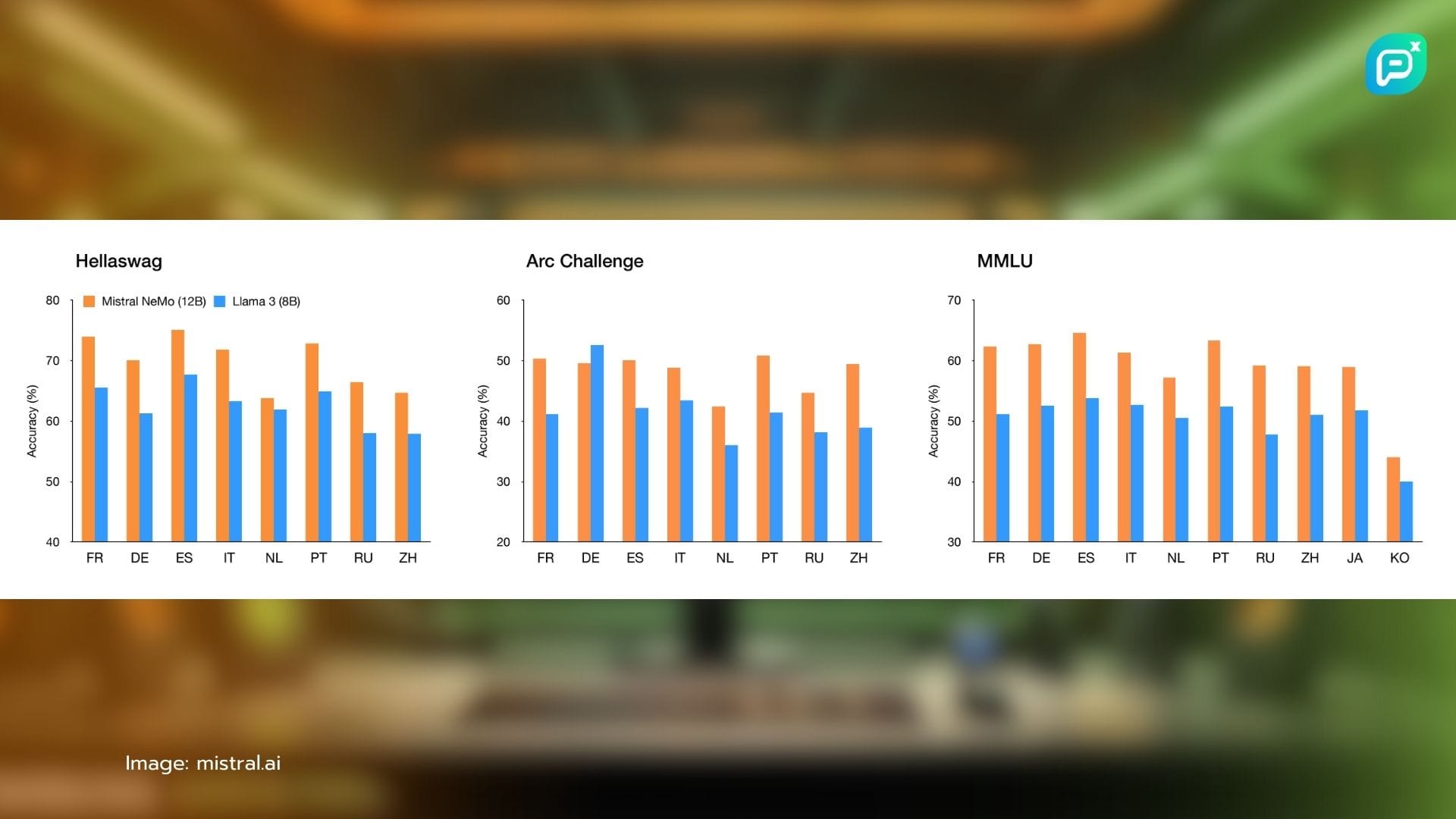
ในขณะที่ธุรกิจในหลากหลายอุตสาหกรรมยังคงต่อสู้กับการผสานรวม AI เข้ากับการดำเนินงานของพวกเขา โมเดลอย่าง Mistral-NeMo ก็เป็นตัวแทนของเทรนด์ที่กำลังเติบโตสู่โซลูชัน AI ที่มีประสิทธิภาพและใช้งานได้มากขึ้น ยังต้องรอดูกันต่อไปว่าสิ่งนี้จะท้าทายการครองตลาดของโมเดลขนาดใหญ่บน cloud หรือไม่ แต่มันเปิดโอกาสใหม่ๆ สำหรับการผสานรวม AI ในสภาพแวดล้อมขององค์กรอย่างแน่นอน
Catanzaro ปิดท้ายการสัมภาษณ์ด้วยแถลงการณ์ที่ว่า “เรามั่นใจว่า AI model ตัวนี้ถือเป็นก้าวสำคัญในการทำให้ AI เข้าถึงได้ง่ายและมีประโยชน์ต่อธุรกิจทุกขนาดมากขึ้น" เขากล่าว "มันไม่ใช่แค่เรื่องของประสิทธิภาพของ model เท่านั้น แต่ยังเกี่ยวกับการนำพลังนั้นไปใส่ไว้ในมือของคนที่สามารถใช้มันเพื่อขับเคลื่อนนวัตกรรมและประสิทธิภาพในการดำเนินงานประจำวันได้โดยตรงอีกด้วย"
ในขณะที่ landscape ของ AI ยังคงพัฒนาอย่างต่อเนื่อง การเปิดตัว Mistral-NeMo ถือเป็นหมุดหมายสำคัญในการเดินทางสู่เครื่องมือ AI ที่เข้าถึงได้ง่าย มีประสิทธิภาพ และทรงพลังมากขึ้นสำหรับธุรกิจ ยังคงต้องรอดูว่าสิ่งนี้จะส่งผลกระทบต่อระบบนิเวศ AI ในวงกว้างอย่างไร แต่สิ่งหนึ่งที่ชัดเจนคือ: การแข่งขันเพื่อนำความสามารถของ AI ไปใกล้ชิดกับผู้ใช้ปลายทางกำลังเข้มข้นขึ้น และ Nvidia กับ Mistral AI เพิ่งทำการเคลื่อนไหวอย่างกล้าหาญไปในทิศทางนั้น
ข้อมูลจาก



